
Google acaba de lanzar DiffusionGemma, un modelo experimental de inteligencia artificial que promete cambiar la forma en que las máquinas escriben textos. Y lo hace con una ventaja impresionante: es hasta cuatro veces más rápido que los modelos tradicionales, como es el caso de ChatGPT.
La gran diferencia de DiffusionGemma está en su enfoque. Mientras que la mayoría de las inteligencias artificiales generan texto palabra por palabra, como alguien que escribe con una máquina de escribir, este nuevo modelo crea y mejora bloques completos de hasta 256 tokens de manera simultánea.
DiffusionGemma promete ser una bestia generativa en los dispositivos de gama alta
DiffusionGemma comienza con marcadores de posición aleatorios y los va refinando mediante múltiples pasos, de forma similar a como funcionan los generadores de imágenes basados en difusión.
Este modelo de 26 mil millones de parámetros, liberado bajo licencia Apache 2.0, activa solo 3,8 mil millones durante su funcionamiento. Gracias a ello, cabe en unos 18 GB de memoria de video, lo que permite ejecutarlo en GPU de alta gama para consumo.
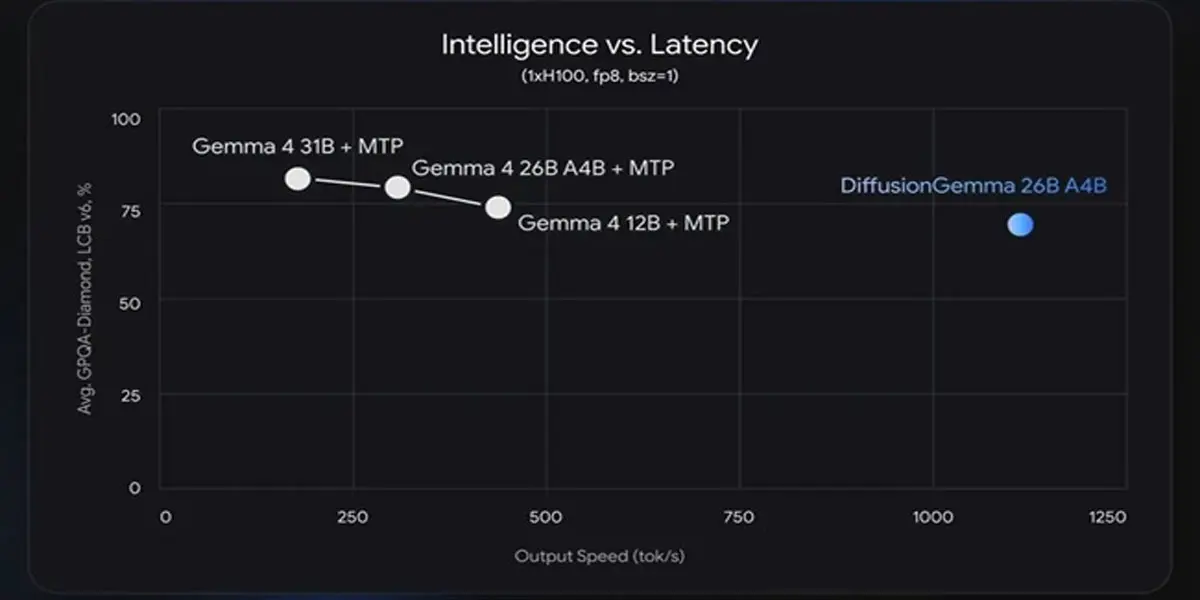
Para ponerlo en perspectiva, puede superar las 1000 palabras por segundo en una GPU NVIDIA H100, y alcanzar unas 700 palabras por segundo en una NVIDIA GeForce RTX 5090. Un usuario con un móvil equipado con hardware compatible podría, en teoría, ejecutar asistentes locales de IA sin depender de la nube.
Google y NVIDIA han trabajado codo a codo para optimizar DiffusionGemma en equipos de escritorio, estaciones de trabajo y sistemas DGX. Esto significa que tanto entusiastas de Apple como usuarios de Samsung pueden aprovechar sus ventajas, siempre que cuenten con el hardware adecuado.

La compañía recomienda este modelo para tareas como edición en línea, relleno de código, estructuras matemáticas o secuencias biológicas, donde la atención bidireccional del sistema permite corregir errores sobre la marcha.
Eso sí, DiffusionGemma prioriza la velocidad sobre la calidad absoluta. Para aplicaciones que exijan los mejores resultados posibles, Google sugiere usar los modelos estándar de la familia Gemma 4. El modelo ya está disponible para descarga en Hugging Face, y se puede probar a través de APIs de NVIDIA o implementarlo localmente en hardware compatible. Próximamente llegará también el soporte oficial para llama.cpp.


")





")






